Basics#

The ReLife’s workflow : from data collection to policy consequences#
The figure above represents the four elementary steps of ReLife’s workflow (for left to right) :
You collect failure data.
You fit a lifetime model from the data.
You create a maintenance policy (preventive age replacement or run-to-failure).
You can project the consequences of the policy (e.g. the expected number of annual replacements).
Data collection#
ReLife provides built-in datasets so that you can start using the library and understand data structures. For this example, we will use the power transformer dataset. If you don’t know what a power transformer is, you can look at the decicated Wikipedia page
>>> from relife.data import load_power_transformer
>>> data = load_power_transformer()
Here data is a structured array that contains three fields :
time: the observed lifetime values.event: boolean values indicating if the event occured during the observation window.entry: the ages of the assets at the beginning of the observation window.
>>> print(data["time"])
[34.3 45.1 53.2 ... 30. 30. 30. ]
>>> print(data["event"])
[ True True True ... False False False]
>>> print(data["entry"])
[34. 44. 52. ... 0. 0. 0.]
Lifetime model estimation#
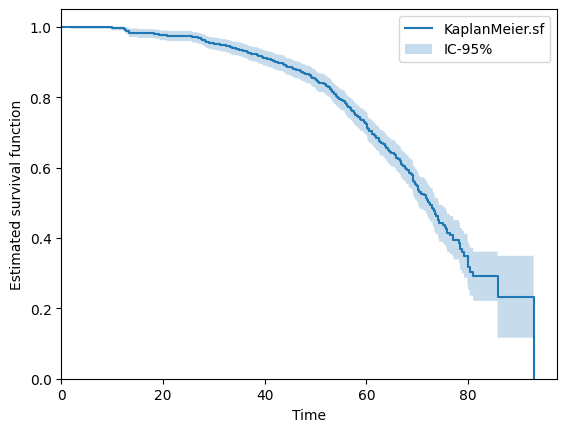
From the data you can fit a lifetime model. It may be a good idea to start with a non-parametric model like a Kaplan-Meier estimator.
>>> from relife.lifetime_model import KaplanMeier
>>> kaplan_meier = KaplanMeier()
>>> kaplan_meier.fit(
data["time"],
event=data["event"],
entry=data["entry"],
)
<relife.lifetime_model.non_parametric.KaplanMeier at 0x732a2f85db90>
You can quickly plot the estimated survival function
>>> kaplan_meier.plot.sf()
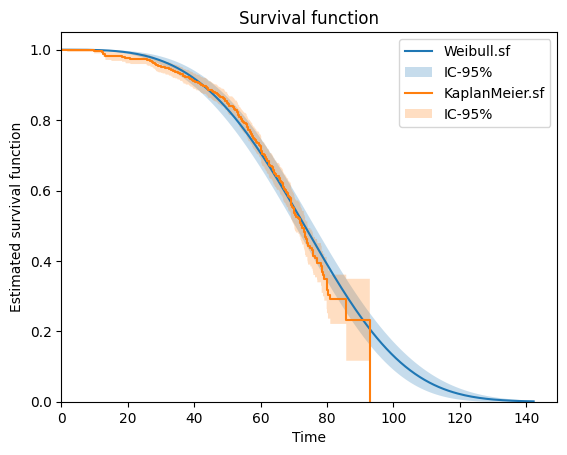
Then, you can fit a parametric lifetime model and plot the two survival functions obtained in one graph.
>>> from relife.lifetime_model import Weibull
>>> weibull = Weibull()
>>> weibull.fit(
data["time"],
event=data["event"],
entry=data["entry"],
)
>>> print(weibull.params_names, weibull.params)
('shape', 'rate') [3.46597396 0.0122785 ]
Note that this object holds params values and the fit method has modified them inplace.
>>> weibull.plot.sf()
>>> kaplan_meier.plot.sf()
Maintenance policy optimization#
Let’s consider that we want the study an age replacement policy. You need to choose :
costs of a preventive replacement \(c_p\)
costs of an unexpected failure \(c_f\)
For this example, we will set \(c_p\) at 3 millions of euros and \(c_f\) at 11 millions of euros. Note that this cost structure also takes into account any undesirable consequences of the asset replacement and that \(c_f\) is higher than \(c_p\). We sample 1000 ages from a binomial distribution to represent the current ages of a flit of 1000 assets.
>>> import numpy as np
>>> cp = 3. # cost of preventive replacement
>>> cf = 11. # cost of failure
>>> a0 = np.random.binomial(60, 0.5, 1000) # asset ages
We can use these values with the previous lifetime model to optimize an age replacement policy
>>> from relife.policy import AgeReplacementPolicy
>>> policy = AgeReplacementPolicy(
weibull,
cf=cf,
cp=cp,
a0=a0,
discounting_rate=0.04,
).optimize()
The obtained object encapsulates optimal ages of replacement ar in one array of 1000 values (because we considered 1000 assets). We can also get the time before the first replacement
by requesting tr1. Here, note that the optimal ages of replacement are the same for each asset because the costs are the same for each of them (but you can also pass arrays of cost values if you want).
>>> print("Optimal ages of replacement (per asset)", policy.ar[:5])
Optimal ages of replacement (per asset) [59.19751205 59.19751205 59.19751205 59.19751205 59.19751205]
>>> print("Current asset ages", policy.a0[:5])
Current asset ages [31 30 25 27 32]
>>> print("Time before the first replacement (per asset)", policy.first_cycle_tr[:5])
Time before the first replacement (per asset) [28.19751205 29.19751205 34.19751205 32.19751205 27.19751205]
Projection of consequences#
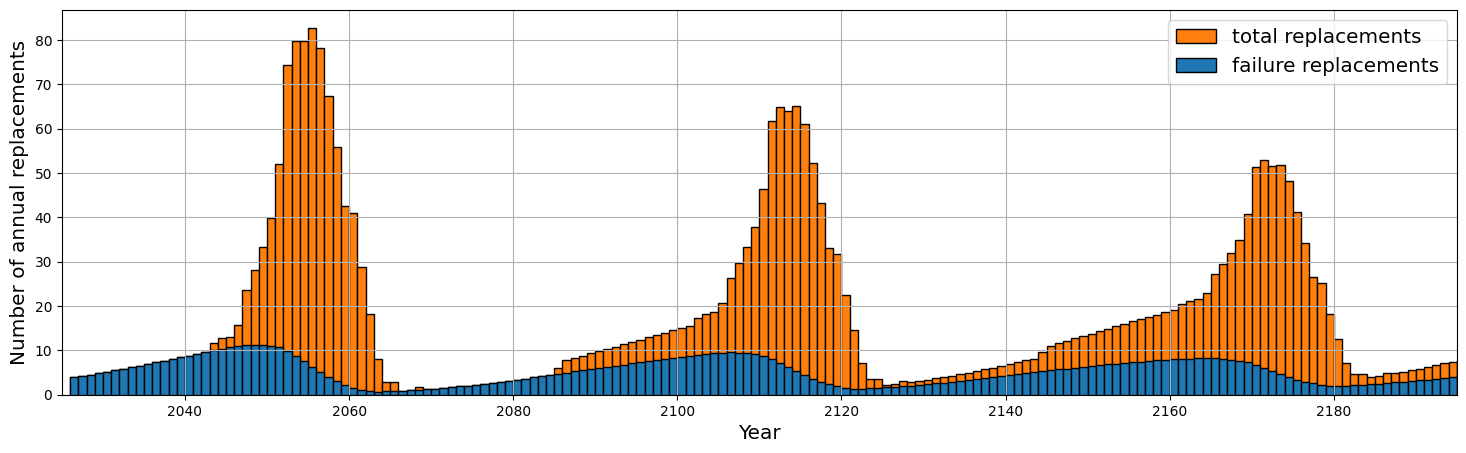
We can project the consequences of our policy, e.g. the expected number of replacements and number of failures for the next 170 years.
>>> nb_years = 170
>>> timeline, nb_replacements, nb_failures = policy.annual_number_of_replacements(nb_years, upon_failure=True)
To do that, ReLife solves the renewal equation. The returned objects are arrays of with 170 values, one value for each upcoming years.
>>> print(timeline.shape)
(170,)
>>> print(nb_replacements.shape)
(170,)
>>> print(nb_failures.shape)
(170,)
Here, ReLife does not offer built-in plot functionnalities. But of course, you can use Matplotlib code to represent these values in one graph.
>>> import matplotlib.pyplot as plt
>>> fig, ax = plt.subplots(figsize=(18, 5), dpi=100)
>>> ax.bar(timeline + 2025, nb_replacements, align="edge", width=1., label="total replacements", color="C1", edgecolor="black")
>>> ax.bar(timeline + 2025, nb_failures, align="edge", width=1., label="failure replacements", color="C0", edgecolor="black")
>>> ax.set_ylabel("Number of annual replacements", fontsize="x-large")
>>> ax.set_xlabel("Year", fontsize="x-large")
>>> ax.set_ylim(bottom=0)
>>> ax.set_xlim(left=2025, right=2025 + nb_years)
>>> ax.legend(loc="upper right", fontsize="x-large")
>>> plt.grid(True)
>>> plt.show()